Design & Engineer







Design & Engineer

gepubliceerd op 15 July
Hoe gebruik je AI (artificial Intelligence) om een dataset te analyseren? Sogelinks’ Data Implementatie Team, zette kunstmatige intelligentie (AI) in om afwijkingen te detecteren in een deel van de Legger-dataset van Waterschap Brabantse Delta. Young Professional Bram Huis vertelt hoe het team te werk ging om afwijkingen (anomalieën) in de Legger-dataset te identificeren.
Deze dataset bevat onder andere wettelijk vastgelegde afmetingen van watergangen en duikers, zoals breedte en diepte. Door digitalisering en menselijke fouten zijn er fouten in deze dataset geslopen. De vraag was: kan AI data-analyse helpen deze fouten op te sporen?
Voordat we ingaan op de oplossing, kijken we naar de verschillende vormen van machine learning en hoe deze helpen bij datakwaliteit verbeteren met AI.
Supervised Learning
Deze methode vereist gelabelde data om een AI-model te trainen. Gelabelde data is een dataset waarin elk datapunt is voorzien van een duidelijke classificatie of label. Dit label geeft aan tot welke categorie een datapunt behoort, zodat het AI – model kan leren van bekende voorbeelden. Het verschil tussen gelabelde en ongelabelde data zijn dat gelabelde data expliciete antwoorden bevat (bijv. “dit is een kat”). Ongelabelde data bevatten alleen ruwe gegevens zonder bekende categorieën, waardoor Unsupervised Learning nodig is om patronen te ontdekken.
Voorbeelden van gelabelde data:
In dit geval zou dat betekenen dat elk object in de dataset al beoordeeld is: is het een anomalie of niet? Dit maakt het model in staat patronen te herkennen en toekomstige afwijkingen correct te voorspellen.
Unsupervised Learning
Hier zijn geen gelabelde gegevens nodig. Het model zoekt patronen en ontdekt afwijkingen zonder vooraf bepaalde categorieën. Dit is ideaal voor anomalie detectie in datasets, waarin onduidelijk is welke objecten fouten bevatten.
Reinforcement Learning
Reinforcement learning is een manier waarop AI leert door fouten te maken en daarvan te leren, net als een kind dat leert fietsen. In het begin valt het kind een paar keer, maar na elke poging wordt het beter in het bewaren van evenwicht en sturen. De AI werkt op dezelfde manier: elke keer dat het een betere beslissing neemt, krijgt het een ‘beloning’. Hierdoor leert het zichzelf gaandeweg te verbeteren.
De oplossing: een mix van AI-modellen
De eerste vraag die we stelden bij dit project was: hebben we voorbeelden van afwijkingen? Het antwoord op deze vraag bepaalde welk type AI data-analyse we konden gebruiken. In de Legger-dataset was onvoldoende gelabelde data aanwezig en het was moeilijk om een mate van ‘beloning’ aan te brengen. Daarom hebben we vijf verschillende unsupervised learning technieken ingezet om om tot een betrouwbare analyse te komen. Elke techniek kent z’n eigen methode:
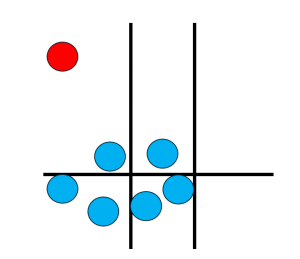 AI als hulpmiddel voor datakwaliteit
AI als hulpmiddel voor datakwaliteit Kortom, deze aanpak toont aan hoe AI en machine learning helpen bij datakwaliteit verbeteren met AI. De keuze voor het juiste AI-model hangt sterk af van de beschikbare data en het gewenste resultaat.
Door met AI verborgen fouten in datasets op te sporen en te corrigeren zetten organisaties een belangrijke stap richting Datagedreven Werken. Dit project laat zien dat AI geen kant-en-klare oplossing is, maar een flexibel hulpmiddel dat slim moet worden afgestemd op de specifieke situatie.

Wil je meer weten over dit onderwerp en hoe jij ook zoiets kan implementeren in jouw organisatie? Neem contact op met ons, onze specialisten staan je graag bij.

published on 29 September
published on 28 August
published on 15 July
published on 2 July